Abandonando o Pooling de Deltas em Favor do Change Data Capture: Uma Abordagem Eficiente para Sincronização de Dados
Autor: Leopoldo Carvalho Correia de Lima
Leitura estimada: 5 min
Data: Aug 19, 2024
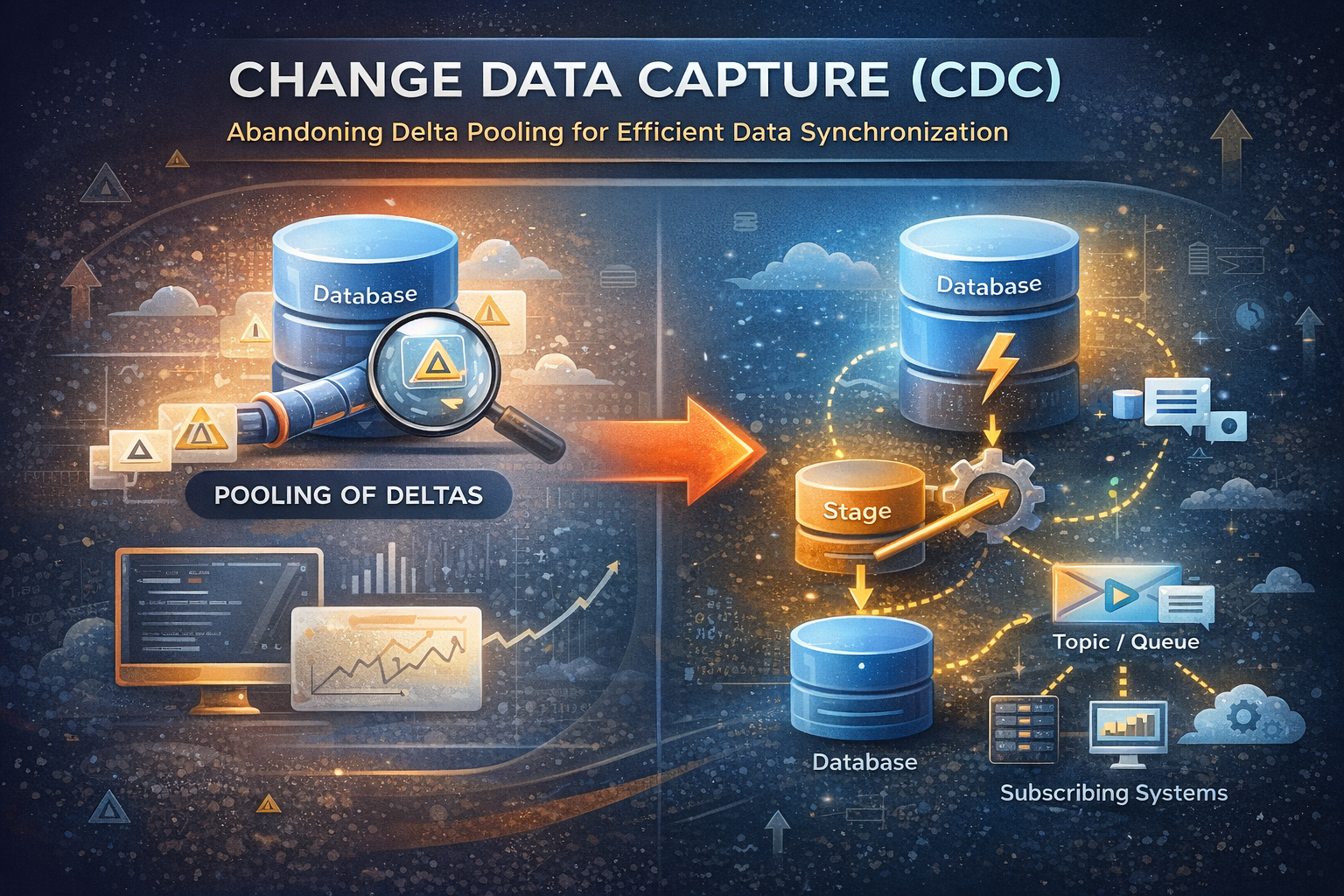
A prática de substituir o pooling de deltas em bases de dados SQL pelo Change Data Capture (CDC) está se tornando cada vez mais relevante, especialmente quando se busca maior integridade e eficiência na sincronização de sistemas. O pooling de deltas, uma técnica tradicionalmente utilizada para monitorar alterações em tabelas transacionais por meio de verificações periódicas, apresenta desafios significativos. Esse método impõe uma sobrecarga substancial ao banco de dados, pois requer varreduras constantes nas tabelas para identificar as mudanças, o que pode degradar o desempenho transacional. Além disso, essa abordagem pode resultar em lacunas na sincronização de dados, aumentando a latência na propagação dos eventos de negócio.
Para mitigar esses riscos, a implementação do CDC surge como uma solução mais eficaz. Nesse modelo, utiliza-se uma tabela de stage em conjunto com um agent para processar os dados alterados. Diferente do pooling de deltas, onde todo o banco de dados ou grandes partes dele precisam ser periodicamente examinadas para identificar mudanças, o CDC trabalha de forma mais inteligente. Uma trigger é configurada na tabela de origem para registrar qualquer modificação diretamente na tabela de stage. Essa abordagem elimina a necessidade de executar varreduras regulares em grandes volumes de dados, capturando apenas as mudanças relevantes no momento em que ocorrem. Como resultado, o banco de dados não é sobrecarregado com operações de leitura intensivas, o que reduz significativamente o consumo de recursos e melhora o desempenho geral do sistema.
Posteriormente, o agent lê esses registros na tabela de stage e os publica em um tópico ou fila, permitindo que sistemas interessados se inscrevam para receber esses eventos em tempo real. Como o CDC captura e propaga as alterações de forma imediata, sem a necessidade de realizar consultas complexas ou comparar grandes conjuntos de dados, ele reduz drasticamente a carga de trabalho no banco de dados. Isso, por sua vez, diminui o uso de CPU, memória e I/O, liberando recursos que podem ser utilizados para outras operações críticas.
Além de consumir menos recursos, o CDC também proporciona benefícios em termos de latência e escalabilidade. O CDC permite que as alterações sejam propagadas quase em tempo real, garantindo que os sistemas consumidores recebam as informações rapidamente e com maior precisão. A arquitetura baseada em eventos, como filas ou tópicos, torna o sistema altamente escalável, permitindo que um número crescente de sistemas consumidores seja atendido sem sobrecarregar a origem dos dados. O uso de um agent para publicar os eventos em tópicos ou filas promove o desacoplamento dos sistemas, facilitando a manutenção e a evolução da arquitetura sem impactos significativos em outros componentes.
A implementação do CDC envolve alguns passos práticos. Primeiramente, configura-se triggers na tabela de origem para capturar inserções, atualizações e deleções, armazenando as alterações na tabela de stage. Em seguida, desenvolve-se o agent, que é responsável por ler os registros da tabela de stage e publicá-los em um tópico ou fila. Esse agent deve garantir que apenas os registros processados sejam marcados, evitando duplicações. A publicação dos dados capturados pode ser feita por meio de sistemas de mensagens, como Apache Kafka ou RabbitMQ, permitindo que os consumidores interessados assinem os tópicos relevantes. Por fim, é crucial implementar mecanismos de monitoramento para assegurar o funcionamento correto do CDC e realizar auditorias regulares para garantir a conformidade e a rastreabilidade dos eventos processados.
A substituição do pooling de deltas pelo CDC não só otimiza a carga e o desempenho do banco de dados, como também oferece uma arquitetura mais escalável e desacoplada. Ao evitar operações de leitura intensivas e focar apenas nas mudanças essenciais, o CDC representa uma solução muito mais eficiente em termos de recursos, especialmente para sistemas que exigem alta disponibilidade e a capacidade de processar grandes volumes de dados em tempo real. A adoção do CDC representa um avanço significativo para organizações que buscam eficiência e resiliência em suas operações de TI.
Abaixo, segue um exemplo de código em Python para a funcionalidade de CDC descrita acima. Vale destacar que este código é apenas um exemplo e deve ser utilizado como inspiração para a construção de uma solução personalizada, adaptada às características e necessidades específicas do sistema em que será implementado.
Estrutura do Projeto
- Arquivo de Configuração (
config.ini) - Código do Agent (
agent.py)
config.ini
[AgentConfig]
BatchSize = 10
TimePooling = 00:05:00 # Formato HH:MM:SS
KafkaTopic = eventos_stage
KafkaBootstrapServers = localhost:9092
MaxRetries = 3 # Máximo de tentativas em caso de falha
LogFileName = agent.log # Nome do arquivo de log
agent.py
import time
import configparser
from kafka import KafkaProducer
from kafka.errors import KafkaError
import logging
# Leitura do arquivo de configuração
config = configparser.ConfigParser()
config.read('config.ini')
# Configuração do Logger usando o arquivo de configuração
LogFileName = config['AgentConfig']['LogFileName']
logging.basicConfig(filename=LogFileName, level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
BatchSize = int(config['AgentConfig']['BatchSize'])
TimePooling = config['AgentConfig']['TimePooling']
KafkaTopic = config['AgentConfig']['KafkaTopic']
KafkaBootstrapServers = config['AgentConfig']['KafkaBootstrapServers']
MaxRetries = int(config['AgentConfig']['MaxRetries'])
# Funções auxiliares
def time_to_seconds(time_str):
h, m, s = map(int, time_str.split(':'))
return h * 3600 + m * 60 + s
# Função de simulação para consultar a tabela stage
def query_stage_table(status, limit):
# Simulação: Retorna uma lista de dicionários simulando registros
return [{'id': i, 'data': f'dado_{i}'} for i in range(1, limit + 1)]
# Função de simulação para atualizar o status dos registros na tabela stage
def update_stage_status(record_id, status):
# Simulação: Atualiza o status do registro com o id fornecido
logging.info(f'Registro {record_id} atualizado para status {status}')
# Função para publicar no Kafka com tratamento de erros
def publish_to_kafka(producer, topic, record):
try:
producer.send(topic, value=record['data'].encode('utf-8')).get(timeout=10)
logging.info(f"Registro {record['id']} publicado no Kafka com sucesso.")
except KafkaError as e:
logging.error(f"Falha ao publicar o registro {record['id']} no Kafka: {e}")
raise
def process_stage_table():
producer = KafkaProducer(bootstrap_servers=KafkaBootstrapServers)
while True:
registros = query_stage_table(status='N', limit=BatchSize)
if registros:
for registro in registros:
update_stage_status(registro['id'], 'P')
for registro in registros:
retries = 0
success = False
while retries < MaxRetries and not success:
try:
publish_to_kafka(producer, KafkaTopic, registro)
update_stage_status(registro['id'], 'C')
success = True
except Exception as e:
retries += 1
logging.error(f"Tentativa {retries}/{MaxRetries} falhou para o registro {registro['id']}. Erro: {e}")
time.sleep(2 ** retries) # Exponential backoff
if not success:
logging.critical(f"Falha crítica: Não foi possível publicar o registro {registro['id']} após {MaxRetries} tentativas.")
# Espera até a próxima execução do polling
time.sleep(time_to_seconds(TimePooling))
if __name__ == "__main__":
logging.info("Iniciando o agent de processamento.")
try:
process_stage_table()
except Exception as e:
logging.critical(f"Erro inesperado: {e}")
Leopoldo Carvalho Correia de Lima é formado pela PUC-SP (Pontifícia Universidade Católica de São Paulo) em Tecnologia e Mídias Digitais com Habilitação em Arte e Tecnologia, turma de 2007, e possui pós-graduação em Gestão e Governança da Tecnologia da Informação pelo SENAC-SP (Serviço Nacional de Aprendizagem Comercial de São Paulo). É especialista em Arquitetura Corporativa. Já trabalhou em empresas renomadas como Accenture, Cargill, Vale, Nextel, Hewlett Packard Co., Carrefour, Bank Boston, Primesys e Banco Santander. Atualmente exerce a função de Arquiteto de Soluções na #META.